隨著企業(yè)的發(fā)展����,客服服務(wù)不可或缺�����?�?头鎸Φ?0%的問題可能都是重復(fù)性的問題����。人工智能的發(fā)展可以大大減輕員工的工作強度和難度。語音識別���、語義理解�����、語音合成技術(shù)的不斷積累和發(fā)展�����,已經(jīng)直接幫助客服處理部分業(yè)務(wù)�����,降低企業(yè)成本����。此外,通過大量的數(shù)據(jù)積累�,客戶服務(wù)中心可以逐步超越成本中心的桎梏,為業(yè)務(wù)部門提供業(yè)務(wù)優(yōu)化方案���,成為更具商業(yè)價值的服務(wù)����。
那么該如何搭建智能客服系統(tǒng)�?
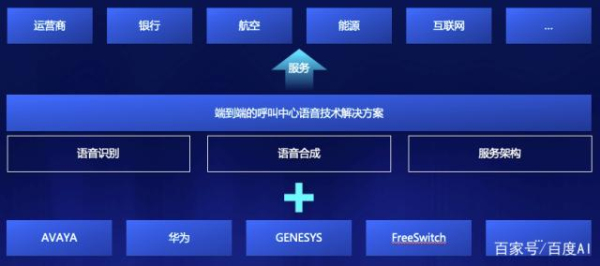
智能客服系統(tǒng)構(gòu)成
呼叫中心平臺:呼叫中心設(shè)備商包括avaya、genesys�、cisco、華為等,同時有很多的集成商及開源方案FreeSWITCH可供選擇�。同時,呼叫平臺也包含運營商電話線路����,企業(yè)可以通過服務(wù)商或?qū)iT的線路集成商獲得。企業(yè)如果還未建立呼叫中心��,則可以根據(jù)自身業(yè)務(wù)情況選擇呼叫中心服務(wù)商或自建呼叫中心����。若已有呼叫中心���,則僅需考慮AI能力部分�。
AI能力:包括語音識別����、語義理解、語音合成等能力�。同時,AI能力要能夠和呼叫中心系統(tǒng)快速對接�。百度語音識別針對呼叫中心8k采樣率音頻及呼叫中心業(yè)務(wù)特征進行專門訓練,采用流式多級的截斷注意力模型(SMLTA)�,國際上首次超越整句的注意力建模、國際上首次實現(xiàn)在線語音大規(guī)模使用注意力模型,通過上千億樣本及十萬小時級訓練數(shù)據(jù)進行高速訓練��。百度呼叫中心語音合成�,針對呼叫中心MRCP8k采用率音頻,進行專門優(yōu)化���,全自動化的海量合成語音數(shù)據(jù)庫制作過程���,通過深度學習的情感拼接合成技術(shù)及神經(jīng)網(wǎng)絡(luò)聲碼器的參數(shù)合成技術(shù),合成效果更流暢自然�,更適合客服場景。
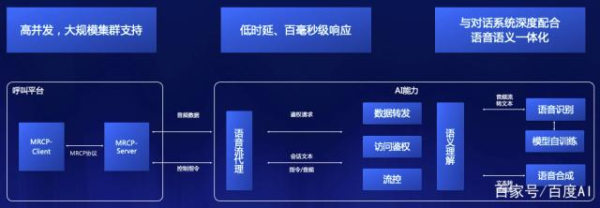
AI能力對接及持續(xù)優(yōu)化
智能客服系統(tǒng)與呼叫中心平臺會有很多交互�����,往往對在系統(tǒng)集成時����,耗費大量時間成本。因此�����,百度基于呼叫中心平臺專門開發(fā)了MRCP端到端解決方案���。使原本幾周的對接時間�,降低為幾天。呼叫中心平臺可直接通過MRCP協(xié)議進行快速對接��。使企業(yè)的呼叫中心平臺或呼叫中心平臺服務(wù)商�,能夠直接對接AI能力。無需大量額外開發(fā)����。
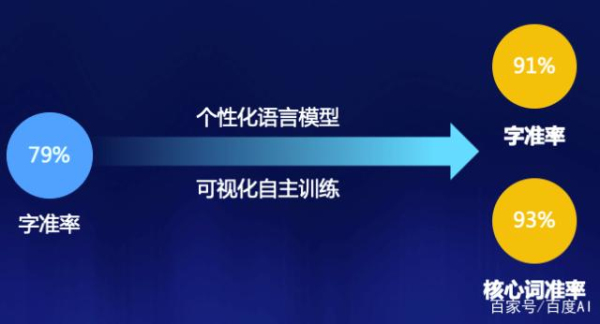
當前AI能力仍處在持續(xù)提升階段,還無法達到非常理想的“強人工智能”階段��。不同的業(yè)務(wù)場景����,也會存在專有名詞識別不準等問題�。百度建立了語音模型自訓練平臺,可以持續(xù)對語言模型進行模型訓練���,提升業(yè)務(wù)專有名詞等問題的識別準確率�。幫助企業(yè)實現(xiàn)定制化模型�,且隨著業(yè)務(wù)的發(fā)展和數(shù)據(jù)的積累,能夠不斷的提升準確率�����。真正達到理想的效果。