看代碼吧~
# 加載庫
import numpy as np
from fancyimpute import KNN
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
# 創(chuàng)建模擬特征矩陣
features, _ = make_blobs(n_samples = 1000,
n_features = 2,
random_state = 1)
# 標準化特征
scaler = StandardScaler()
standardized_features = scaler.fit_transform(features)
standardized_features
# 制造缺失值
true_value = standardized_features[0,0]
standardized_features[0,0] = np.nan
standardized_features
# 預(yù)測
features_knn_imputed = KNN(k=5, verbose=0).fit_transform(standardized_features)
# features_knn_imputed = KNN(k=5, verbose=0).complete(standardized_features)
features_knn_imputed
# #對比真實值和預(yù)測值
print("真實值:", true_value)
print("預(yù)測值:", features_knn_imputed[0,0])
# 加載庫
import numpy as np
from fancyimpute import KNN
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
# 創(chuàng)建模擬特征矩陣
features, _ = make_blobs(n_samples = 1000,
n_features = 2,
random_state = 1)
# 標準化特征
scaler = StandardScaler()
standardized_features = scaler.fit_transform(features)
standardized_features
# 制造缺失值
true_value = standardized_features[0,0]
standardized_features[0,0] = np.nan
standardized_features
# 預(yù)測
features_knn_imputed = KNN(k=5, verbose=0).fit_transform(standardized_features)
# features_knn_imputed = KNN(k=5, verbose=0).complete(standardized_features)
features_knn_imputed
# #對比真實值和預(yù)測值
print("真實值:", true_value)
print("預(yù)測值:", features_knn_imputed[0,0])
真實值: 0.8730186113995938
預(yù)測值: 1.0955332713113226
補充:scikit-learn中一種便捷可靠的缺失值填充方法:KNNImputer
在數(shù)據(jù)挖掘工作中���,處理樣本中的缺失值是必不可少的一步���。其中對于缺失值插補方法的選擇至關(guān)重要���,因為它會對最后模型擬合的效果產(chǎn)生重要影響。
在2019年底��,scikit-learn發(fā)布了0.22版本���,此次版本除了修復(fù)之前的一些bug外��,還更新了很多新功能�,對于數(shù)據(jù)挖掘人員來說更加好用了�。其中我發(fā)現(xiàn)了一個新增的非常好用的缺失值插補方法:KNNImputer。這個基于KNN算法的新方法使得我們現(xiàn)在可以更便捷地處理缺失值��,并且與直接用均值�����、中位數(shù)相比更為可靠���。利用“近朱者赤”的KNN算法原理��,這種插補方法借助其他特征的分布來對目標特征進行缺失值填充���。
下面�,就讓我們用實際例子來看看KNNImputer是如何使用的吧
使用KNNImputer需要從scikit-learn中導(dǎo)入:
from sklearn.impute import KNNImputer
先來一個小例子開開胃�,data中第二個樣本存在缺失值。
data = [[2, 4, 8], [3, np.nan, 7], [5, 8, 3], [4, 3, 8]]
KNNImputer中的超參數(shù)與KNN算法一樣�����,n_neighbors為選擇“鄰居”樣本的個數(shù)��,先試試n_neighbors=1����。
imputer = KNNImputer(n_neighbors=1)
imputer.fit_transform(data)

可以看到,因為第二個樣本的第一列特征3和第三列特征7��,與第一行樣本的第一列特征2和第三列特征8的歐氏距離最近��,所以缺失值按照第一個樣本來填充��,填充值為4�。那么n_neighbors=2呢���?
imputer = KNNImputer(n_neighbors=2)
imputer.fit_transform(data)

此時根據(jù)歐氏距離算出最近相鄰的是第一行樣本與第四行樣本�����,此時的填充值就是這兩個樣本第二列特征4和3的均值:3.5���。
接下來讓我們看一個實際案例��,該數(shù)據(jù)集來自Kaggle皮馬人糖尿病預(yù)測的分類賽題�,其中有不少缺失值����,我們試試用KNNImputer進行插補。
import numpy as np
import pandas as pd
import pandas_profiling as pp
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context="notebook", style="darkgrid")
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from sklearn.impute import KNNImputer
#Loading the dataset
diabetes_data = pd.read_csv('pima-indians-diabetes.csv')
diabetes_data.columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness',
'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
diabetes_data.head()
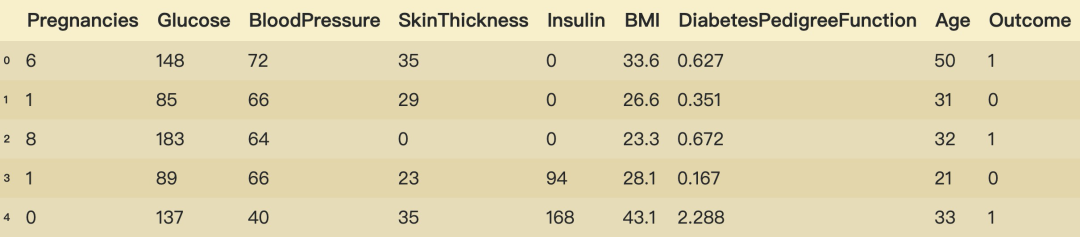
在這個數(shù)據(jù)集中���,0值代表的就是缺失值��,所以我們需要先將0轉(zhuǎn)化為nan值然后進行缺失值處理�。
diabetes_data_copy = diabetes_data.copy(deep=True)
diabetes_data_copy[['Glucose','BloodPressure','SkinThickness','Insulin','BMI']] = diabetes_data_copy[['Glucose','BloodPressure','SkinThickness','Insulin','BMI']].replace(0, np.NaN)
print(diabetes_data_copy.isnull().sum())
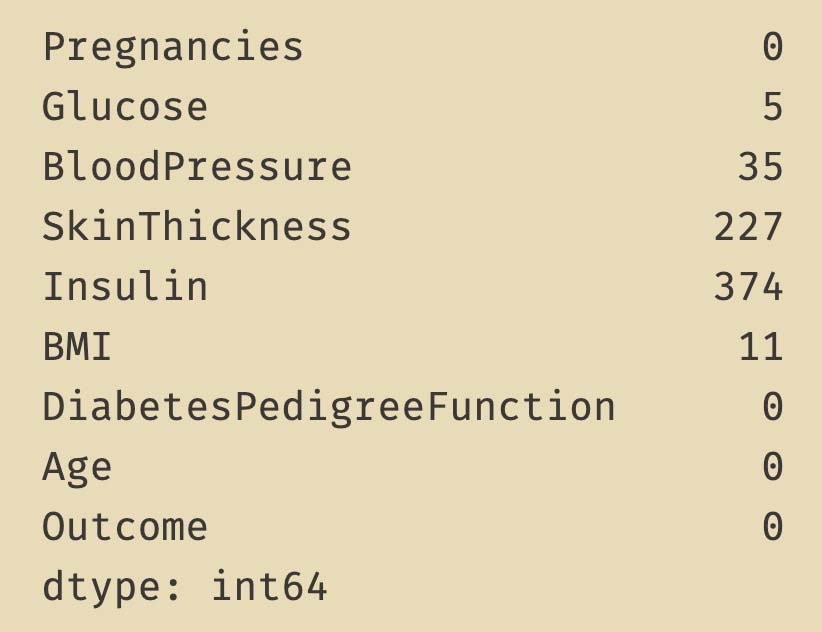
在本文中�,我們嘗試用DiabetesPedigreeFunction與Age,對BloodPressure中的35個缺失值進行KNNImputer插補��。
先來看一下缺失值都在哪幾個樣本:
null_index = diabetes_data_copy.loc[diabetes_data_copy['BloodPressure'].isnull(), :].index
null_index

imputer = KNNImputer(n_neighbors=10)
diabetes_data_copy[['BloodPressure', 'DiabetesPedigreeFunction', 'Age']] = imputer.fit_transform(diabetes_data_copy[['BloodPressure', 'DiabetesPedigreeFunction', 'Age']])
print(diabetes_data_copy.isnull().sum())

可以看到現(xiàn)在BloodPressure中的35個缺失值消失了���。我們看看具體填充后的數(shù)據(jù)(只截圖了部分):
diabetes_data_copy.iloc[null_index]

到此����,BloodPressure中的缺失值已經(jīng)根據(jù)DiabetesPedigreeFunction與Age運用KNNImputer填充完成了。注意的是�����,對于非數(shù)值型特征需要先轉(zhuǎn)換為數(shù)值型特征再進行KNNImputer填充操作���,因為目前KNNImputer方法只支持數(shù)值型特征(ʘ̆ωʘ̥̆‖)՞����。
您可能感興趣的文章:- python實現(xiàn)KNN近鄰算法
- Python圖像識別+KNN求解數(shù)獨的實現(xiàn)
- python KNN算法實現(xiàn)鳶尾花數(shù)據(jù)集分類
- python運用sklearn實現(xiàn)KNN分類算法
- 使用python實現(xiàn)kNN分類算法
- python實現(xiàn)KNN分類算法
- python使用KNN算法識別手寫數(shù)字
- Python機器學(xué)習(xí)之底層實現(xiàn)KNN
