目錄
- 概率抽樣技術(shù)
- 1.隨機抽樣(Random Sampling)
- 2.分層抽樣(Stratified Sampling)
- 3.聚類抽樣(Cluster Sampling)
- 4.系統(tǒng)抽樣(Systematic Sampling)
- 5.多級采樣(Multistage sampling)
- 非概率抽樣技術(shù)
- 1.簡單采樣(convenience sampling)
- 2.自愿抽樣(Voluntary Sampling)
- 3.雪球抽樣(Snowball Sampling)
- 總結(jié)
今天來和大家聊聊抽樣的幾種常用方法�,以及在Python中是如何實現(xiàn)的。
抽樣是統(tǒng)計學、機器學習中非常重要,也是經(jīng)常用到的方法,因為大多時候使用全量數(shù)據(jù)是不現(xiàn)實的��,或者根本無法取到�����。所以我們需要抽樣��,比如在推斷性統(tǒng)計中�����,我們會經(jīng)常通過采樣的樣本數(shù)據(jù)來推斷估計總體的樣本�。
上面所說的都是以概率為基礎(chǔ)的�����,實際上還有一類非概率的抽樣方法����,因此總體上歸納為兩大種類:
概率抽樣:根據(jù)概率理論選擇樣本,每個樣本有相同的概率被選中�。
非概率抽樣:根據(jù)非隨機的標準選擇樣本,并不是每個樣本都有機會被選中�。
概率抽樣技術(shù)
1.隨機抽樣(Random Sampling)
這也是最簡單暴力的一種抽樣了,就是直接隨機抽取����,不考慮任何因素,完全看概率�。并且在隨機抽樣下,總體中的每條樣本被選中的概率相等��。

比如��,現(xiàn)有10000條樣本�,且各自有序號對應(yīng)的,假如抽樣數(shù)量為1000�,那我就直接從1-10000的數(shù)字中隨機抽取1000個,被選中序號所對應(yīng)的樣本就被選出來了����。
在Python中,我們可以用random函數(shù)隨機生成數(shù)字��。下面就是從100個人中隨機選出5個����。
import random
population = 100
data = range(population)
print(random.sample(data,5))
> 4, 19, 82, 45, 41
2.分層抽樣(Stratified Sampling)
分層抽樣其實也是隨機抽取�,不過要加上一個前提條件了��。在分層抽樣下���,會根據(jù)一些共同屬性將帶抽樣樣本分組��,然后從這些分組中單獨再隨機抽樣��。
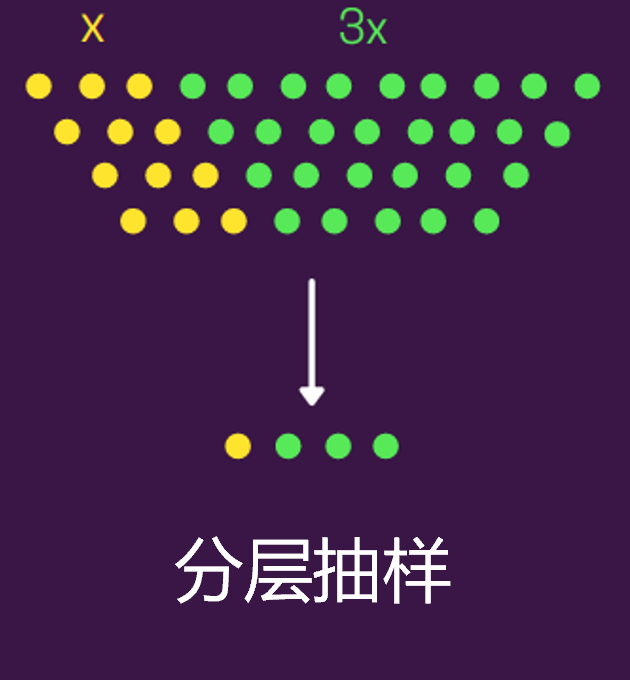
因此����,可以說分層抽樣是更精細化的隨機抽樣��,它要保持與總體群體中相同的比例�����。 比如���,機器學習分類標簽中的類標簽0和1�����,比例為3:7����,為保持原有比例����,那就可以分層抽樣,按照每個分組單獨隨機抽樣����。
Python中我們通過train_test_split設(shè)置stratify參數(shù)即可完成分層操作。
from sklearn.model_selection import train_test_split
stratified_sample, _ = train_test_split(population, test_size=0.9, stratify=population[['label']])
print (stratified_sample)
3.聚類抽樣(Cluster Sampling)
聚類抽樣����,也叫整群抽樣。它的意思是��,先將整個總體劃分為多個子群體��,這些子群體中的每一個都具有與總體相似的特征��。也就是說它不對個體進行抽樣���,而是隨機選擇整個子群體�����。
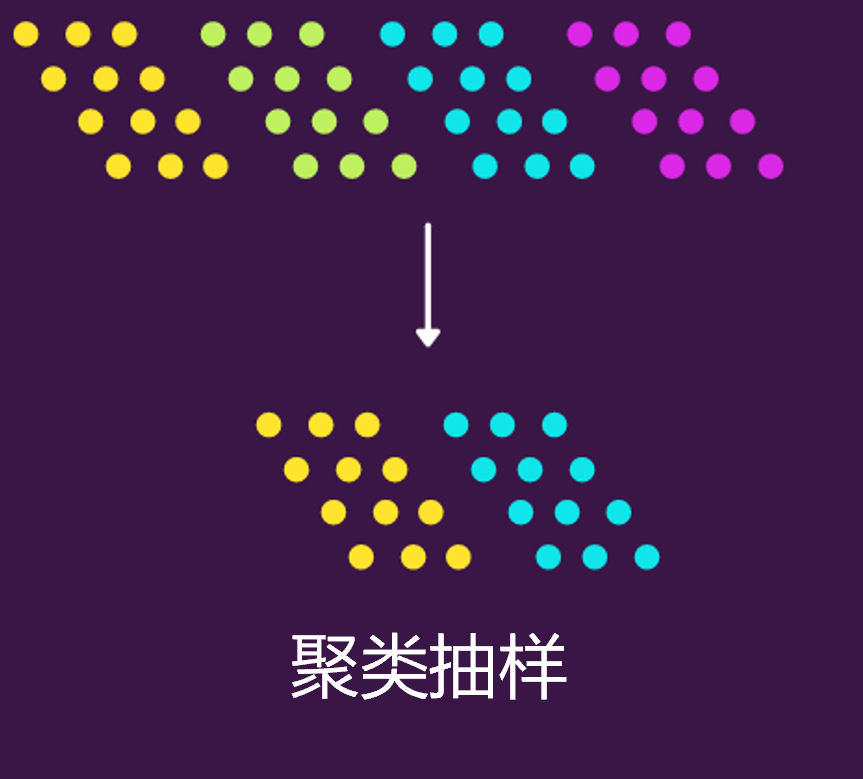
用Python可以先給聚類的群體分配聚類ID���,然后隨機抽取兩個子群體����,再找到相對應(yīng)的樣本值即可��,如下����。
import numpy as np
clusters=5
pop_size = 100
sample_clusters=2
# 間隔為 20, 從 1 到 5 依次分配集群100個樣本的聚類 ID,這一步已經(jīng)假設(shè)聚類完成
cluster_ids = np.repeat([range(1,clusters+1)], pop_size/clusters)
# 隨機選出兩個聚類的 ID
cluster_to_select = random.sample(set(cluster_ids), sample_clusters)
# 提取聚類 ID 對應(yīng)的樣本
indexes = [i for i, x in enumerate(cluster_ids) if x in cluster_to_select]
# 提取樣本序號對應(yīng)的樣本值
cluster_associated_elements = [el for idx, el in enumerate(range(1, 101)) if idx in indexes]
print (cluster_associated_elements)
4.系統(tǒng)抽樣(Systematic Sampling)
系統(tǒng)抽樣是以預(yù)定的規(guī)則間隔(基本上是固定的和周期性的間隔)從總體中抽樣。比如,每 9 個元素抽取一下��。一般來說,這種抽樣方法往往比普通隨機抽樣方法更有效��。
下圖是按順序?qū)γ?9 個元素進行一次采樣����,然后重復下去。
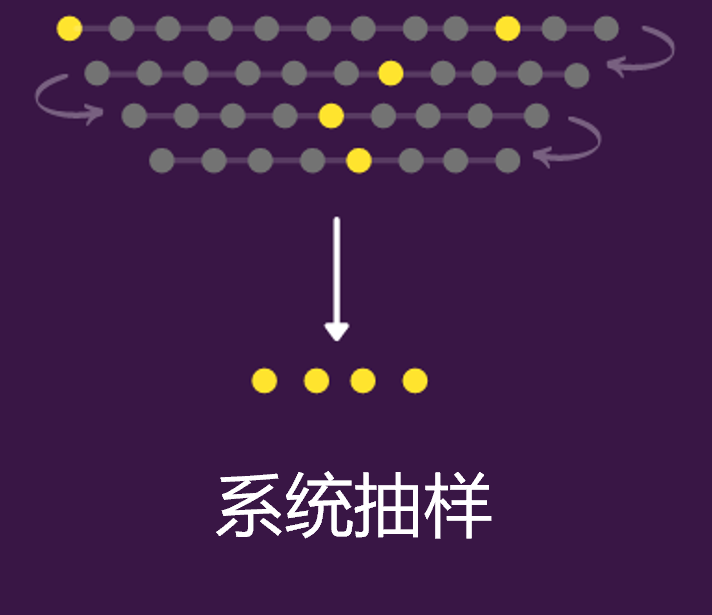
用Python實現(xiàn)的話可以直接在循環(huán)體中設(shè)置step即可�����。
population = 100
step = 5
sample = [element for element in range(1, population, step)]
print (sample)
5.多級采樣(Multistage sampling)
在多階段采樣下,我們將多個采樣方法一個接一個地連接在一起�����。比如����,在第一階段�����,可以使用聚類抽樣從總體中選擇集群��,然后第二階段再進行隨機抽樣���,從每個集群中選擇元素以形成最終集合���。

Python代碼復用了上面聚類抽樣,只是在最后一步再進行隨機抽樣即可���。
import numpy as np
clusters=5
pop_size = 100
sample_clusters=2
sample_size=5
# 間隔為 20, 從 1 到 5 依次分配集群100個樣本的聚類 ID���,這一步已經(jīng)假設(shè)聚類完成
cluster_ids = np.repeat([range(1,clusters+1)], pop_size/clusters)
# 隨機選出兩個聚類的 ID
cluster_to_select = random.sample(set(cluster_ids), sample_clusters)
# 提取聚類 ID 對應(yīng)的樣本
indexes = [i for i, x in enumerate(cluster_ids) if x in cluster_to_select]
# 提取樣本序號對應(yīng)的樣本值
cluster_associated_elements = [el for idx, el in enumerate(range(1, 101)) if idx in indexes]
# 再從聚類樣本里隨機抽取樣本
print (random.sample(cluster_associated_elements, sample_size))
非概率抽樣技術(shù)
非概率抽樣�,毫無疑問就是不考慮概率的方式了�����,很多情況下是有條件的選擇��。因此���,對于無隨機性我們是無法通過統(tǒng)計概率和編程來實現(xiàn)的�。這里也介紹3種方法����。
1.簡單采樣(convenience sampling)
簡單采樣,其實就是研究人員只選擇最容易參與和最有機會參與研究的個體��。比如下面的圖中����,藍點是研究人員,橙色點則是藍色點附近最容易接近的人群�����。
2.自愿抽樣(Voluntary Sampling)
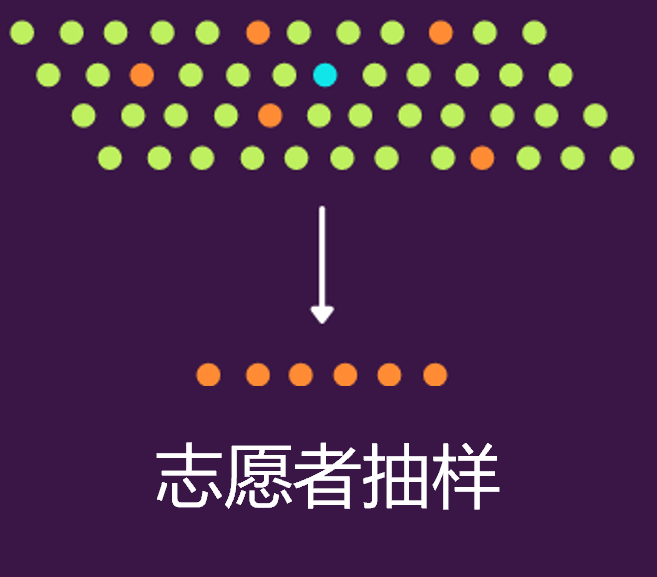
自愿抽樣下,感興趣的人通常通過填寫某種調(diào)查表格形式自行參與的�����。所以��,這種情況中�,調(diào)查的研究人員是沒有權(quán)利選擇任何個體的���,全憑群體的自愿報名�。比如下圖中藍點是研究人員����,橙色的是自愿同意參與研究的個體。
3.雪球抽樣(Snowball Sampling)
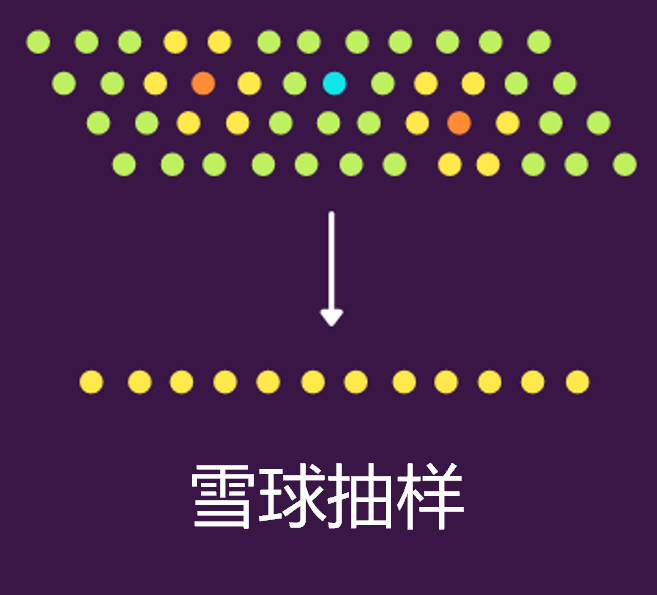
雪球抽樣是說�,最終集合是通過其他參與者選擇的,即研究人員要求其他已知聯(lián)系人尋找愿意參與研究的人��。比如下圖中藍點是研究人員�,橙色的是已知聯(lián)系人,黃色是是橙色點周圍的其它聯(lián)系人����。
總結(jié)
以上就是8種常用抽樣方法����,平時工作中比較常用的還是概率類抽樣方法��,因為沒有隨機性我們是無法通過統(tǒng)計學和編程完成自動化操作的���。
比如在信貸的風控樣本設(shè)計時��,就需要從樣本窗口通過概率進行抽樣����。因為采樣的質(zhì)量基本就決定了你模型的上限了�����,所以在抽樣時會考慮很多問題�����,如樣本數(shù)量����、是否有顯著性、樣本穿越等等。在這時���,一個良好的抽樣方法是至關(guān)重要的�。
到此這篇關(guān)于Python實現(xiàn)8種常用抽樣方法的文章就介紹到這了,更多相關(guān)Python 抽樣方法內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家��!
您可能感興趣的文章:- python使用pandas抽樣訓練數(shù)據(jù)中某個類別實例
- python實現(xiàn)的分層隨機抽樣案例
- python數(shù)據(jù)預(yù)處理 :數(shù)據(jù)抽樣解析
- 基于python進行抽樣分布描述及實踐詳解
- python Pandas如何對數(shù)據(jù)集隨機抽樣
