目錄
- 一、順序查找算法
- 二�����、折半查找算法
- 三����、插補查找算法
- 四、哈希查找算法
- 五��、分塊查找算法
- 六���、斐波那契查找算法
- 七���、六種查找算法的時間復雜度
一、順序查找算法
順序查找又稱為線性查找����,是最簡單的查找算法。這種算法就是按照數據的順序一項一項逐個查找����,所以不管數據順序如何,都得從頭到尾地遍歷一次��。順序查找的優(yōu)點就是數據在查找前�����,不需要對其進行任何處理(包括排序)�����。缺點是查找速度慢����,如果數據列的第一個數據就是想要查找的數據,則該算法查找速度為最快����,只需查找一次即可;如果查找的數據是數據列的最后一個(第幾個)�����,則該算法查找速度為最慢����,需要查找 n 次����,甚至還會出現未找到數據的情況��。
例如���,有這樣一組數據:10��、27�、13�、14、19��、85�����、70�����、29��、69、27���。如果想要查找數據 19,需要進行 5 次查找�;如果想要查找數據 27,需要進行 10 次查找�����;如果想要查找數據 10�,只需要進行 1 次查找。
從這個例子中可以看出�����,當查找的數據較多時�,用順序查找就不太合適,所以說順序查找只能應用于查找數據較少的數據列����。這個過程好比我們在抽屜里找筆,如下圖所示���。通常情況下我們會從上層的抽屜開始��,一層一層地查找�����,直到找到筆為止���,這個例子就是生活中典型的順序查找算法�。

例如�����,隨機從 1~100 之間生成 50 個整數�����,并將隨機生成的這 50 個數顯示出來��,然后用順序查找算法查找16�����、45���、97這幾個數據的位置�����。具體代碼如下:
import random # 導入隨機數模塊
num = 0 # 定義變量num
# 使用列表推導式生成包含50個元素的列表
data = [random.randint(1, 100) for i in range(50)]
print("隨機產生的數據內容是:")
for i in range(10): # 遍歷行
for j in range(5): # 遍歷列
# 按格式輸出隨機生成內容
print('%2d[%3d] ' % (i * 5 + j + 1, data[i * 5 + j]), end='')
print('')
while num != -1: # 循環(huán)輸入
find = 0 # 比較次數
num = int(input("請輸入想要查找的數據���,輸入-1退出程序:")) # 數據輸入
for i in range(50): # 循環(huán)遍歷50個隨機數
if data[i] == num: # 判斷輸入數據和data數據是否相等
print("在", i + 1, "個位置找到數據", data[i]) # 輸出找到的位置和數據內容
find += 1 # 比較次數加1
if find == 0 and num != -1: # 判斷比較次數是否為0且輸入數據是否為-1
print("沒有找到", num, "此數據") # 提示沒有找到數據
程序運行結果如下圖所示:

二�、折半查找算法
折半查找算法又稱為二分查找算法���,折半查找算法是將數據分割成兩等份,首先用鍵值(要查找的數據)與中間值進行比較�����。如果鍵值小于中間值��,可確定要查找的鍵值在前半段����;如果鍵值大于中間值,可確定要查找的鍵值在后半段���。然后對前半段(后半段)進行分割�,將其分成兩等份����,再對比鍵值�����。如此循環(huán)比較��、分割��,直到找到數據或者確定數據不存在為止�����。折半查找的缺點是只適用于已經初步排序好的數列�;優(yōu)點是查找速度快�。
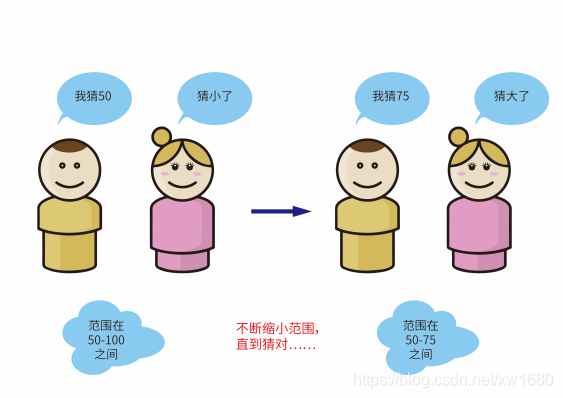
生活中也有類似于折半查找的例子,例如���,猜數字游戲����。在游戲開始之前����,首先會給出一定的數字范圍(例如0~100)����,并在這個范圍內選擇一個數字作為需要被猜的數字�。然后讓用戶去猜,并根據用戶猜的數字給出提示(如猜大了或猜小了)���。用戶通常的做法就是先在大范圍內隨意說一個數字�����,然后提示猜大了/猜小了,這樣就縮小了猜數字的范圍�����,慢慢地就猜到了正確的數字���,如下圖所示����。這種做法與折半查找法類似��,都是通過不斷縮小數字范圍來確定數字�,如果每次猜的范圍值都是區(qū)間的中間值��,就是折半查找算法了��。
例如�,已經有 排序好 的數列:12��、45��、56����、66、77�����、80�、97、101���、120���,要查找的數據是 101,用折半查找步驟如下:
步驟1:將數據列出來并找到中間值 77�,將 101 與 77 進行比較����,如下圖所示�����。

步驟2:將 101 與 77 進行比較�����,結果是 101 大于 77��,說明要查找的數據在數列的右半段��。此時不考慮左半段的數據���,對在右半段的數據再進行分割,找中間值�。這次中間值的位置在 97 和 101 之間,取 97��,將 101 與 97 進行比較���,如下圖所示���。

步驟3:將 101 與 97 進行比較����,結果是 101 大于 97����,說明要查找的數據在右半段數列中,此時不考慮左半段的數據�,再對剩下的數列分割,找中間值����,這次中間值位置是 101,將 101 與 101 進行比較�����,如下圖所示�。

步驟4:將 101 與 101 進行比較,所得結果相等�,查找完成。說明:如果多次分割之后沒有找到相等的值�,表示這個鍵值沒有在這個數列中。
從折半法查找的步驟來看,明顯比順序查找法的次數少����,這就是折半查找法的優(yōu)點:查找速度快。
有一條的150米線路�,在這條線路上存在故障。第一天維修工已經大致鎖定了幾個疑似故障點��,疑似故障點分別在線路的12�、45、56�、66、77��、80����、97、101��、120米處���。第二天維修工要在這9個疑似故障點中確定一個真正的故障點(假設真正的故障點是101米處)。維修工為了快速查找此故障點�����,就在每段數據的中間位置開始排查。
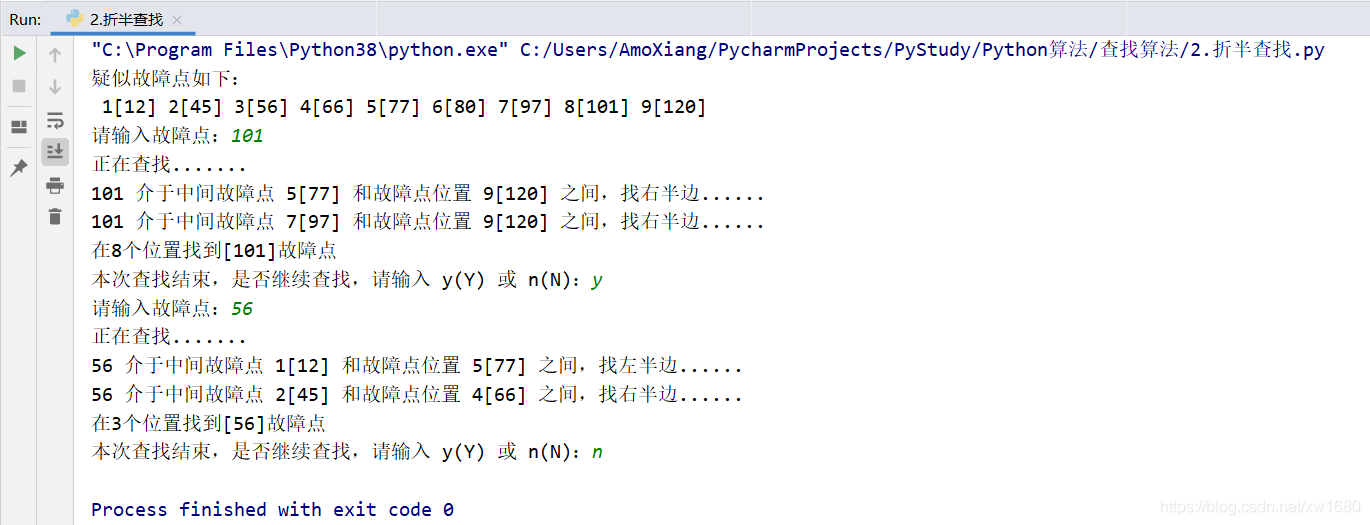
例如����,第一次選擇在77米處的疑似故障點接通電路,發(fā)現接通���,他判斷此故障在77米之后的位置�;第二次取97米處的疑似故障點���,發(fā)現也接通了����,說明在97米之后的位置���;第三次取101米處的位置�����,再次接通線路����,發(fā)現未接通,說明此處是真正的故障點���。此次查找經歷了3次��,將真正故障點找到��。具體代碼如下:
def search(data, num):
"""
定義查找函數:該函數使用的是折半查找算法
:param data: 原數列data
:param num: 鍵值num
:return:
"""
low = 0 # 定義變量用來表示低位
high = len(data) - 1 # 定義變量用來表示高位
print("正在查找.......") # 提示
while low = high and num != -1:
mid = int((low + high) / 2) # 取中間位置
if num data[mid]: # 判斷數據是否小于中間值
# 輸出位置在數列中的左半邊
print(f"{num} 介于中間故障點 {low + 1}[{data[low]}] 和故障點位置 {mid + 1}[{data[mid]}] 之間�,找左半邊......")
high = mid - 1 # 最高位變成了中間位置減1
elif num > data[mid]: # 判斷數據是否大于中間值
# 輸出位置在數列中的右半邊
print(f"{num} 介于中間故障點 {mid + 1}[{data[mid]}] 和故障點位置 {high + 1}[{data[high]}] 之間�����,找右半邊......")
low = mid + 1 # 最低位變成了中間位置加1
else: # 判斷數據是否等于中間值
return mid # 返回中間位置
return -1 # 自定義函數到此結束
inp_num = 0 # 定義變量�,用來輸入鍵值
num_list = [12, 45, 56, 66, 77, 80, 97, 101, 120] # 定義數列
print("疑似故障點如下:")
for index, ele in enumerate(num_list):
print(f" {index + 1}[{ele}]", end="") # 輸出數列
print("")
flag = True # 開關,用來管控是否多次查找
while flag: # 循環(huán)查找
inp_num = int(input("請輸入故障點:").strip()) # 輸入查找鍵值
if inp_num == -1: # 判斷鍵值是否是-1
break # 若為-1�,跳出循環(huán) 即結束程序
result = search(num_list, inp_num) # 調用自定義的查找函數——search()函數
if result == -1: # 判斷查找結果是否是-1
print(f"沒有找到[{inp_num}]故障點") # 若為-1,提示沒有找到值
else:
# 若不為-1�����,提示查找位置
print(f"在{result + 1}個位置找到[{num_list[result]}]故障點")
char = input("本次查找結束����,是否繼續(xù)查找,請輸入 y(Y) 或 n(N):").strip()
if char.upper() == "N":
flag = False
程序執(zhí)行結果如下圖所示:
三��、插補查找算法
插補查找算法又稱為插值查找�����,它是折半查找算法的改進版���。插補查找是按照數據的分布�,利用公式預測鍵值所在的位置����,快速縮小鍵值所在序列的范圍,慢慢逼近�,直到查找到數據為止。根據描述來看�,插值查找類似于平常查英文字典的方法。例如�,在查一個以字母 D 開頭的英文單詞時,決不會用折半查找法�。根據英文詞典的查找順序可知,D 開頭的單詞應該在字典較前的部分���,因此可以從字典前部的某處開始查找�。鍵值的索引計算����,公式如下:
middle=left+(target-data[left])/(data[right]-data[left])*(right-left)
參數說明:
- middle:所求的邊界索引�。
- left:最左側數據的索引���。
- target:鍵值(目標數據)�����。
- data[left]:最左側數據值����。
- data[right]:最右側數據值���。
- right:最右側數據的索引����。
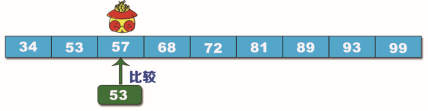
例如��,已經有排序好的數列:34�、53、57����、68�����、72、81����、89、93�����、99��。要查找的數據是 53��,使用插補查找法步驟如下:
步驟1:將數據列出來并利用公式找到邊界值�,計算過程如下:
將各項數據帶入公式:

將數據取整,因此所求索引是 2����,對應的數據是 57,將查找目標數據 53 與 57 進行比較��,如下圖所示���。
步驟2:將 53 與 57 進行比較����,結果是 53 小于 57,所以查找 57 的左半邊數據�����,不用考慮右半邊的數據����,索引范圍縮小到 0 和 2 之間,公式帶入:

取整之后索引是 1����,對應的數據是 53,將查找目標數據 53 與 53 進行比較�����,如下圖所示:

步驟3:將 53 與 53 進行比較���,所得結果相等�����,查找完成���。說明:如果多次分割之后沒有找到相等的值����,表示這個鍵值沒有在這個數列中��。
通過上述的步驟1就能看出�,插補查找算法比折半查找算法的取值范圍更小��,因此它的速度要比折半法查找快�����,這就是插補查找算法的優(yōu)點�。
用戶可以隨意輸入一組數據,例如本實例輸入一組數據:34��、53���、57��、68��、72���、81��、89�、93�����、99���。在這組數據中用插補查找法分別查找數據 57��、53�����、93��、89��、100���,且顯示每次查找的過程���。用 Python 代碼實現此過程,具體代碼如下:
def insert_search(data, num):
"""
自定義查找函數:該函數使用的是插補查找算法
:param data: 原數列data
:param num: 鍵值num
:return:
"""
# 計算
left_index = 0 # 最左側數據的索引
right_index = len(data) - 1 # 最右側數據的索引
print("正在查找.......") # 提示
while left_index = right_index:
# 使用公式計算出索引值
middle = left_index + (num - data[left_index]) / (data[right_index] - data[left_index]) * (
right_index - left_index)
# 取整
middle = int(middle)
# print(middle)
if num == data[middle]:
return middle # 如果鍵值等于邊界值�,返回邊界位置
elif num data[middle]:
# 輸出位置在數列中的左半邊
print(f"{num} 介于位置{left_index + 1}[{data[left_index]}]和邊界值{middle + 1}[{data[middle]}]之間,找左半邊......")
right_index = middle - 1 # 如果鍵值小于邊界值����,最右邊數據索引等于邊界位置減1
else:
# 輸出位置在數列中的左半邊
print(f"{num} 介于位置{middle + 1}[{data[middle]}]和邊界值{right_index + 1}[{data[right_index]}]之間,找右半邊......")
left_index = middle + 1 # 如果鍵值大于邊界值��,最左邊數據索引等于邊界位置加1
return -1 # 自定義函數到此結束
inp_num = 0 # 定義變量��,用來輸入鍵值
num_list = [34, 53, 57, 68, 72, 81, 89, 93, 99] # 定義數列
print("數據內容是:")
for index, ele in enumerate(num_list):
print(f" {index + 1}[{ele}]", end="") # 輸出數列
print("")
flag = True # 開關���,用來管控是否多次查找
while flag: # 循環(huán)查找
inp_num = int(input("請輸入要查找的鍵值:").strip()) # 輸入查找鍵值
result = insert_search(num_list, inp_num) # 調用自定義的查找函數——insert_search()函數
if result == -1: # 判斷查找結果是否是-1
print(f"沒有找到[{inp_num}]") # 若為-1,提示沒有找到值
else:
# 若不為-1���,提示查找位置
print(f"在{result + 1}個位置找到[{inp_num}]")
char = input("本次查找結束�����,是否繼續(xù)查找�����,請輸入 y(Y) 或 n(N):").strip()
if char.upper() == "N":
flag = False
程序執(zhí)行結果如下圖所示:

四��、哈希查找算法
哈希查找算法是使用哈希函數來計算一個鍵值所對應的地址��,進而建立哈希表格�,然后利用哈希函數來查找到各個鍵值存放在表格中的地址。簡單來說����,就是把一些復雜的數據,通過某種函數映射(與數學中的映射概念一樣)關系�����,映射成更加易于查找的方式�。哈希查找算法的查找速度與數據多少無關,完美的哈希查找算法一般都可以做到一次讀取完成查找��。
就像生活中��,要想找到自己想要的物品�,最好的辦法就是把該物品固定在某個地方,每次需要用到它的時候就去對應的地方找��,用完之后再放回原處。哈希查找法就是這樣的一種算法�,例如,在一本書中查找內容���,首先翻開這本書的目錄�,然后在目錄上找到想要的內容��,最后直接根據對應的頁碼就能找到所需要的內容�。
哈希查找算法具有保密性高的特點,因此哈希查找算法常被應用在數據壓縮和加解密方面����。常見的哈希算法有除留取余法、平方取中法以及折疊法����。在講解這三種算法之前����,首先需要了解 哈希表 和 哈希函數 的概念。
1. 哈希表和哈希函數
哈希表是存儲鍵值和鍵值所對應地址的一種數據集合��。哈希表中的位置��,一般稱為槽位,每個槽位都能保存一個數據元素并以一個整數命名(從 0 開始)���。這樣我們就有了0號槽位���、1號槽位等。起始時����,哈希表里沒有數據,槽位是空的���,這樣在構建哈希表時�,可以把槽位的值都初始化成 None����,如下圖所示。

這是一個大小為 11 的哈希表�����,或者說有 n 個槽位的哈希表�,n 為0~10。上圖中的元素和保存的槽位之間的映射關系����,稱為哈希函數����。哈希函數接受一個元素作為參數��,返回一個0到n-1的整數作為槽位名����。說明:每種哈希算法的哈希函數和哈希表,會在每種哈希算法中介紹�����。
2. 除留余數法
除留余數法是哈希算法中最簡單的一種算法����。它是將每個數據除以某個常數后,取余數來當索引�����。除留取余法所對應的哈希函數形式如下:
參數說明:
- item:每個數據����。
- num:一個常數,一般會選擇一個質數�,如下面的例子中取質數 11。
例如���,將整數集:54�、26�、93、17�����、77�����、31 中每個數據都除以 11�����,所得的余數作為哈希值���,哈希值如下表所示���。

注意:除留余數法一般以某種形式存于所有哈希函數中�,因為它的運算結果一定在槽位范圍內���。哈希值計算出來之后�����,就要把元素插入到哈希表中指定的位置�����,如下圖所示��。

則對應的哈希函數也得到了哈希值�,如:h(54)=10����,h(26)=4,h(93)=5���,h(17)=6����,h(77)=0,h(31)=9��。
3. 折疊法
對給定的數據集��,哈希函數將每個元素映射為單個槽位�����,稱為 完美哈希函數���。但是對于任意一個數據集合,沒有系統(tǒng)能構造出完美哈希函數����。例如,在上述除留余數法的例子中再加上一個數據 44�����,該數字除以 11 后�����,得到的余數是 0��,這與數據 77 的哈希值相同���。遇到這種情況時����,解決辦法之一就是擴大哈希表,但是這種做法太浪費空間���。因此又有了擴展除留取余數的方案����,也就是折疊法���。
折疊法是將數據分成一串數據�����,先將數據拆成幾部分�����,再把它們加起來作為哈希地址����。例如,有這樣一串數據:5205211314��,將這串數據中的數字兩兩分一組�,如下圖所示:

然后將拆的數據進行相加,如下圖所示:
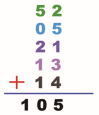
相加之后得到的數值就是這串數據的哈希地址��,如果設定槽位是 11�,用除留余數法將哈希地址除以 11��,得到的值是 6�����,而數據 6 就是這串數據的哈希值�,這種做法稱為 移動折疊法。
有些折疊法多了一步���,就是在相加之前��,對數據進行奇數或偶數反轉���,再將反轉后的數字相加。下圖所示就是將奇數反轉的過程��,再將反轉后的數據相加,得到的 159 也稱為哈希地址�����。

此時設定槽位是 11����,將哈希地址除以 11,得到的值是 5��,數據 5 就是這個數據的哈希值����。接下來介紹將偶數反轉的情況,如下圖所示���。

將上圖中反轉后的數據相加�����,得到的 105 也稱為哈希地址�。如果設定槽位是 11���,除留余數法將哈希地址除以 11����,得到的值是 6,數據 6 就是這個數據的哈希值��。奇數/偶數反轉這種折疊法稱為 邊界折疊法��。
4. 平方取中法
平方取中法是先將各個數據平方��,將平方后數據取中間的某段數字作為索引�����,例如��,對于整數集 54���,26,93�,17,77�,31,平方取中法如下:
步驟1:先將各個數據平方��,得到的值如下:
54=2916
26=676
93=8649
17=289
77=5929
31=961
步驟2:取以上平方值的中間數�����,即取十位和百位,得到該整數集中數據的哈希地址分別為:
91 67 64 28 92 96
步驟3:若設置槽位是 11��,將步驟 2 得到的數據分別除以 11 留余數��,得到的哈希值分別為:
3 1 9 6 4 8
得到的對應關系如下圖所示:

5. 碰撞與溢出問題
哈希算法的理想情況是所有數據經過哈希函數運算后得到不同的值�,但是在實際情況中即使得到的哈希值不同,也有可能得到相同的地址�,這種問題被稱為 碰撞問題。使用哈希算法�,將數據放到哈希表中存儲數據的對應位置,若該位置滿了��,就會溢出�,這種問題被稱為 溢出問題。存在問題就需要解決問題���,如何解決碰撞問題與溢出問題很重要����。由于常見的解決問題方法有多種�,故在后續(xù)博文中進行更新。
實例:用哈希查找算法查找七色光顏色��。具體代碼如下:
class HashTable(object): # 創(chuàng)建哈希表
def __init__(self):
self.size = 11 # 哈希表長度
self.throw = [None] * self.size # 哈希表數據鍵初始化
self.data = [None] * self.size # 哈希表數據值初始化
# 假定最終將有一個空槽,除非 key 已經存在于 self. throw中�。它計算原始
# 哈希值,如果該槽不為空�,則迭代 rehash 函數,直到出現空槽�。如果非空槽已經包含key,
# 則舊數據值將替換為新數據值
def put(self, key, value): # 輸出鍵值
hashvalue = self.hashfunction(key, len(self.throw)) # 創(chuàng)建哈希值
if self.throw[hashvalue] is None:
self.throw[hashvalue] = key # 將key值給哈希表的throw
self.data[hashvalue] = value # 將value值給哈希表的data
else:
if self.throw[hashvalue] == key:
self.data[hashvalue] = value
else:
nextslot = self.rehash(hashvalue, len(self.throw))
while self.throw[nextslot] is not None and self.throw[nextslot] != key:
nextslot = self.rehash(nextslot, len(self.throw))
if self.throw[nextslot] is None:
self.throw[nextslot] = key
self.data[nextslot] = value
else:
self.data[nextslot] = value
def rehash(self, oldhash, size):
return (oldhash + 1) % size
def hashfunction(self, key, size):
return key % size
# 從計算初始哈希值開始����。如果值不在初始槽中,則 rehash 用
# 于定位下一個可能的位置��。
def get(self, key):
startslot = self.hashfunction(key, len(self.throw))
data = None
found = False
stop = False
pos = startslot
while pos is not None and not found and not stop:
if self.throw[pos] == key:
found = True
data = self.data[pos]
else:
pos = self.rehash(pos, len(self.throw))
# 回到了原點�,表示找遍了沒有找到
if pos == startslot:
stop = True
return data
# 重載載 __getitem__ 和 __setitem__ 方法以允許使用 [] 訪問
def __getitem__(self, key):
return self.get(key)
def __setitem__(self, key, value):
return self.put(key, value)
H = HashTable() # 創(chuàng)建哈希表
H[16] = "紅" # 給哈希表賦值
H[28] = "橙"
H[32] = "黃"
H[14] = "綠"
H[56] = "青"
H[36] = "藍"
H[71] = "紫"
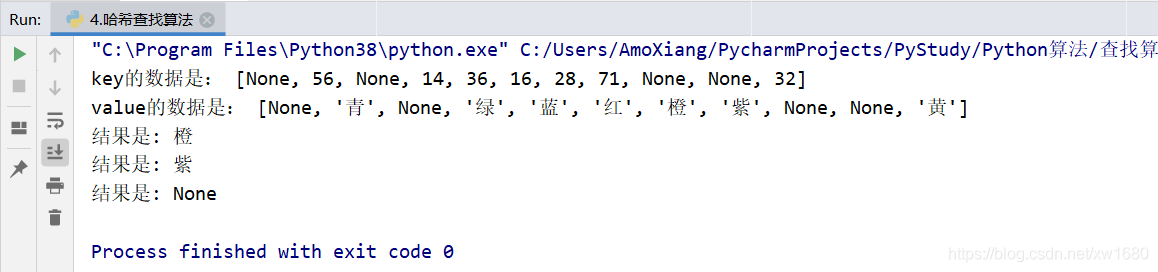
print("key的數據是:", H.throw) # 輸出鍵key
print("value的數據是:", H.data) # 輸出值value
print("結果是:", H[28]) # 根據key=28查value
print("結果是:", H[71]) # 根據key=71查value
print("結果是:", H[93]) # 根據key=93查value
程序執(zhí)行結果如下圖所示:
五、分塊查找算法
分塊查找是二分法查找和順序查找的改進方法�����,分塊查找要求索引表是有序的���,對塊內結點沒有排序要求,塊內結點可以是有序的也可以是無序的��。
分塊查找就是把一個大的線性表分解成若干塊����,每塊中的節(jié)點可以任意存放���,但塊與塊之間必須排序。與此同時�,還要建立一個索引表,把每塊中的最大值作為索引表的索引值����,此索引表需要按塊的順序存放到一個輔助數組中。查找時����,首先在索引表中進行查找,確定要找的結點所在的塊���。由于索引表是排序的��,因此����,對索引表的查找可以采用順序查找或二分查找���;然后���,在相應的塊中采用順序查找�����,即可找到對應的結點��。
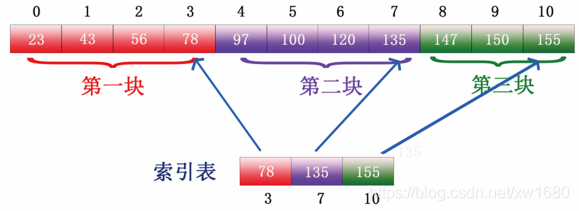
例如��,有這樣一列數據:23����、43��、56����、78、97��、100���、120、135�、147��、150�����。如下圖所示:

想要查找的數據是 150��,使用分塊查找法步驟如下:
步驟1:將上圖所示的數據進行分塊�,按照每塊長度為 4 進行分塊�����,分塊情況如下圖所示:

說明:每塊的長度是任意指定的�����,博主在這里用的長度為4�����,讀者可以根據自己的需要指定每塊長度�����。
步驟2:選取各塊中的最大關鍵字構成一個索引表,即選取上圖所示的各塊的最大值�����,第一塊最大的值是 78�,第二塊最大的值是 135,第三塊最大值是 155�����,形成的索引表如下圖所示:
步驟3:用順序查找或者二分查找判斷想要查找數據 150 在上圖所示的索引表中的哪塊內容中�����,這里博主用的是二分查找法����,即先取中間值 135 與 150 比較,如下圖所示:

步驟4:結果是中間位置的數據 135 比目標數據 150 小����,因此目標數據在 135 的下一塊內。將數據定位在第 3 塊內�,此時將第 3 塊內的數據取出,進行順序比較��,如下圖所示:

步驟5:通過順序查找第 3 塊的內容�,終于在第 9 個位置找到目標數,此時分塊查找結束�。
總結:至此,分塊查找算法已經講解完畢���。通過和二分查找法和順序查找法對比來看����,分塊查找的速度雖然不如二分查找算法�����,但比順序查找算法快得多����。當數據很多且塊數很大時,對索引表可以采用二分查找���,這樣能夠進一步提高查找的速度�����。
實例:實現分塊查找算法�。具體代碼如下:
def search(data, key): # 用二分查找 想要查找的數據在哪塊內
length = len(data) # 數據列表長度
first = 0 # 第一位數位置
last = length - 1 # 最后一個數據位置
print(f"長度:{length} 分塊的數據是:{data}") # 輸出分塊情況
while first = last:
mid = (last + first) // 2 # 取中間位置
if data[mid] > key: # 中間數據大于想要查的數據
last = mid - 1 # 將last的位置移到中間位置的前一位
elif data[mid] key: # 中間數據小于想要查的數據
first = mid + 1 # 將first的位置移到中間位置的后一位
else:
return mid # 返回中間位置
return False
# 分塊查找
def block(data, count, key): # 分塊查找數據,data是列表�����,count是每塊的長度��,key是想要查找的數據
length = len(data) # 表示數據列表的長度
block_length = length // count # 一共分的幾塊
if count * block_length != length: # 每塊長度乘以分塊總數不等于數據總長度
block_length += 1 # 塊數加1
print("一共分", block_length, "塊") # 塊的多少
print("分塊情況如下:")
for block_i in range(block_length): # 遍歷每塊數據
block_data = [] # 每塊數據初始化
for i in range(count): # 遍歷每塊數據的位置
if block_i * count + i >= length: # 每塊長度要與數據長度比較�����,一旦大于數據長度
break # 就退出循環(huán)
block_data.append(data[block_i * count + i]) # 每塊長度要累加上一塊的長度
result = search(block_data, key) # 調用二分查找的值
if result != False: # 查找的結果不為False
return block_i * count + result # 就返回塊中的索引位置
return False
data = [23, 43, 56, 78, 97, 100, 120, 135, 147, 150, 155] # 數據列表
result = block(data, 4, 150) # 第二個參數是塊的長度����,最后一個參數是要查找的元素
print("查找的值得索引位置是:", result) # 輸出結果
運行結果如下圖所示:

從上面的運行結果看到,當查找 150 時�,查找結果完全符合上述描述的步驟。
六�、斐波那契查找算法
斐波那契查找也稱為黃金分割法查找,是在二分查找的基礎上根據斐波那契數列進行分割����,二分法是取排序好的中間值進行分割,而斐波那契查找是根據黃金分割點進行分割�����。想要掌握斐波那契查找,首先需要了解兩個概念�����,一個是黃金分割點��,另一個是斐波那契數列����。
黃金分割點���。黃金分割點是指把一條線段分割為兩部分�,使其中一部分與全長之比等于另一部分與這部分之比�,其比值取其前三位數字的近似值是 0.618。0.618 是一個神奇的數字���,在建筑學和設計學等方面���,按照按此比例設計的造型就會十分美麗,因此稱為黃金分割���。這個分割點就叫作黃金分割點�����。斐波那契數列��。斐波那契數列����,又稱黃金分割數列,指的是這樣一個數列:1���、1�、2���、3�、5�����、8�����、13���、21�����、34�����、55……��,在數學上����,斐波那契被遞歸方法如下定義:F(1)=1�,F(2)=1,F(n) = F(n-1)+F(n-2) (n>=2)�����。斐波那契數列越往后�����,前后兩項的比值越接近 0.618�,也就是黃金比例的比值���。
斐波那契查找就是在二分查找的基礎上根據斐波那契數列進行分割的。在斐波那契數列找一個等于或略大于待查找表長度的數 F(n)�,待查找表長度擴展為 F(n)-1(如果原來數組長度不夠 F(n)-1,則需要擴展����,擴展時候用原待查找表最后一項填充),mid = low + F(n-1) -1��,已知 mid 為劃分點�����,將待查找表劃分為左邊����,右邊,即 F(n) 個元素分割為前半部分 F(n-1)-1 個元素�����,后半部分 F(n-2)-1 個元素�,如圖下圖所示:

說明:假如待查找列表長度為 F(n),不考慮 mid 的情況下����,左邊為 F(n - 1)��,右邊為 F(n -2)����,考慮 mid 的情況下要不左邊是 F(n-1) - 1 或者右邊是 F(n - 2) - 1����,邏輯不好寫,如果待查找長度為 F(n) - 1��,mid = low + (F(n - 1) - 1) 則不存在這樣的問題����。
例如�,已經有排序好的數列:9、10�����、13�、15、22�����、29、37�、48、53�,要查找的數據是 37,如下圖所示:

用斐波那契查找法步驟如下:
說明:斐波那契查找也和二分查找法一樣��,需要在查找前���,將數列排序好�����。
步驟1:先來看一下原始數據的長度���,如上圖所示長度是 9,再來看斐波那契數列 1����、1、2��、3、5��、8����、13、21���、34�����、55····���,從數據來看,最接近的數字是 13���,因此將原始數據的長度擴展到 13,用上圖的最后一個數據 53 補齊�。如下圖所示:

步驟2:接下來得找查找算法里的中間值了,首先假設創(chuàng)建斐波那契數列為 F(n)��,斐波那契數列的規(guī)律 F(n)= F(n-1)+ F(n-2)�,上圖已經將原數列長度補充到 13,在斐波那契數列中 13=8+5,即 F(6)=F(5)+F(4)����,則中間是 F(5),在斐波那契數列中 F(5)=8���,因此 mid=low+F(5)-1=7����。如下圖所示:

步驟3:從數據上看�����,mid=7 對應的數據是 48�����,目標數據 37 比 48 小���,因此再次尋找以 mid 為分割線的左側部分數據����,此時 high 的值從 8 的位置變?yōu)?mid-1 的位置�����,即此時 high=6,low 值不變���,依然是 0����。如下圖所示:

步驟4:此時圖中所示的數據長度變成了 7��,再次找此時數據的中間值�,數據長度 7 與斐波那契數列的數字 8 比較接近,8=3+5�����,8 在斐波那契數列中是 F(5)�,即 F(5)=F(4)+F(3),中間值是 F(4)���,在斐波那契數列中 F(4)=5,此時的 mid=low+F(4)-1=4�����。如下圖所示:

步驟5:從數據上看,mid=4 對應的數據是 22���。目標數據 37 比 22 大���,因此再次尋找以 mid為 分割線的右側部分數據,此時 low 的值從 0 的位置變?yōu)?mid+1 的位置�,即此時 low=5,high 值不變�����,依然是 6�����,如下圖所示:

步驟6:從上圖可知 high=6�,最接近的斐波那契數列的數據是 8,8=3+5����,8 在斐波那契數列中是 F(5),即 F(5)=F(4)+F(3)���,虛擬中間值是 F(4)��,因為是在中間值的右側尋找�,因此需要計算 F(n-2)=F(4-2)=F(2),在斐波那契數列中 F(2)=2�����,此時的 mid=low+F(2)-1=5+1=6���,如下圖所示:

步驟7:從數據上看��,mid=4 對應的數據是 37��,目標數據 37 等于中間值 37�����,此時返回尋找的位置��,即返回 mid 的位置����。如果計算 mid 的值大于 high 的值��,就之間返回 high 的值�。此時已經用斐波那契查找完成尋找目標數據 37 的任務。
總結來說:斐波那契查找與二分查找很相似��,它是根據斐波那契序列的特點對有序表進行分割的���。它要求開始表中記錄的個數為某個斐波那契數小 1�,即 k=F(n)-1;開始將 n 值與第 F(n-1) 位置的記錄進行比較 (即 mid=low+F(n-1)-1)����,比較結果也分為三種:
相等,mid 位置的元素即為所求��。n > F(n-1) 位置的記錄����,low=mid+1,n-=2����。說明:low=mid+1 說明待查找的元素在 [mid+1,hign](即右側)范圍內,n-=2 說明范圍 [mid+1,high] 內的元素個數為 k-(F(n-1))= F(n)-1-F(n-1)=F(n)-F(n-1)-1=F(n-2)-1 個����,所以可以遞歸的應用斐波那契查找。n F(n-1)位置的記錄 �����,high=mid-1,n-=1�����。說明:low=mid+1 說明待查找的元素在 [low,mid-1](即左側)范圍內�,k-=1 說明范圍 [low,mid-1] 內的元素個數為 F(k-1)-1 個,所以可以遞歸的應用斐波那契查找���。
接下來用Python代碼來實現以上描述的斐波那契查找����。
def fibonacci_search(data, key):
# 需要一個現成的斐波那契列表��。其最大元素的值必須超過查找表中元素個數的數值
F = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,
233, 377, 610, 987, 1597, 2584, 4181, 6765]
low = 0 # 低位
high = len(data) - 1 # 高位
# 為了使得查找表滿足斐波那契特性��,在表的最后添加幾個同樣的值
# 這個值是原查找表的最后那個元素的值
# 添加的個數由F[k]-1-high決定
k = 0
while high > F[k] - 1:
k += 1
i = high # 將i定位到high的位置
while F[k] - 1 > i: # 添加數據
data.append(data[high]) # 追加到high之后的位置上
i += 1
print("添加后的數據", data) # 輸出追加后的數據
# 算法主邏輯�����,count用于展示循環(huán)的次數
while low = high: # 滿足低位小于等于高位
# 為了防止F列表下標溢出����,設置if和else
if k 2:
mid = low
else:
mid = low + F[k - 1] - 1
print("低位位置:%s, 中間位置:%s,高位位置:%s" % (low, mid, high)) # 輸出每次分割情況
if key data[mid]: # 目標數據小于中間值數據�,在左側尋找
high = mid - 1 # 高位位置移到mid-1的位置
k -= 1 # 下標k此時減1
elif key > data[mid]: # 目標數據大于中間值數據�,在右側尋找
low = mid + 1 # 低位位置移到mid+1的位置
k -= 2 # 下標k此時減2
else: # 否則
if mid = high: # 中間值小于等于mid
return mid # 此時的結果是mid就是目標值得位置,返回mid即可
else: # 如果mid大于了高位位置值
return high # 此時的結果直接返回high的值
return False
# 驗證數據
data = [9, 10, 13, 15, 22, 29, 37, 48, 53] # 數據列表
key = int(input("請輸入想要查找的數據:"))
result = fibonacci_search(data, key) # 調用斐波那契查找函數
print("目標數據", key, "的位置是", result) # 輸出結果
運行結果如下圖所示:

從上圖中的運行結果看到�����,當查找 37 時����,查找結果完全符合上述描述的步驟�。如果想要進行其他數據的查找,都可以通過斐波那契查找算法實現���,這里就不一一講解了����。
七����、六種查找算法的時間復雜度
在第 1~6 節(jié)中介紹了六種查找算法,本節(jié)就用大 O 表示法來比較一下這四種查找算法的時間復雜度�。先來總結這四種查找算法的基本思想:
- 順序查找算法:按照數據的順序一項一項逐個查找,所以不管數據順序如何�,都要從頭到尾的遍歷一次����。速度比較慢���,它的時間復雜度是 T=O(n)�����。
- 二分查找算法:將數據分割成兩等份���,然后用鍵值(要查找的數據)與中間值比較,逐漸縮短查找范圍�。速度比順序查找快,它的時間復雜度是 T=O(log n)�����。
- 插補查找算法:按照數據的分布�,利用公式預測鍵值所在的位置,快速縮小鍵值所在序列的范圍����,慢慢逼近,直到查找到數據為止,這種算法比二分查找速度還快����,它的時間復雜度是 T=O(log log(n))。
- 分塊查找算法:要求是順序表�����,它是順序查找的一種改進方法�����,它的時間復雜度是 T= O(log2(m)+N/m)�����。
- 斐波那契查找算法:斐波那契查找就是在二分查找的基礎上根據斐波那契數列進行分割的���。用鍵值(要查找的數據)與黃金分割點進行比較,逐漸縮短查找范圍��。它的時間復雜度是 T=O(log 2n)�。
- 哈希查找算法:把一些復雜的數據,通過某種函數映射(概念和數學中映射一樣)關系�,映射成更加易于查找的方式。這種方法速度最快,它的時間復雜度是 T=O(1)��。
六種查找算法的時間復雜度如下表所示:

到此這篇關于Python 語言實現六大查找算法的文章就介紹到這了,更多相關python查找算法內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- PHP局部異常因子算法-Local Outlier Factor(LOF)算法的具體實現解析
- java排序算法圖文詳解
- Java實現雪花算法的原理和實戰(zhàn)教程
- c++ Bellman-Ford算法的具體實現
- Java實現常見排序算法的優(yōu)化
- 異常點/離群點檢測算法——LOF解析
