目錄
- 安裝 Selenium
- 寫代碼
- 點位網(wǎng)頁元素
我們今天介紹一個非常適合新手的python自動化小項目�����,項目雖小��,但是五臟俱全����。它是一個自動化操作網(wǎng)頁瀏覽器的小應(yīng)用:打開瀏覽器���,進入百度網(wǎng)頁,搜索關(guān)鍵詞�,最后把搜索結(jié)果保存到一個文件里。這個例子非常適合新手學習Python網(wǎng)絡(luò)自動化��,不僅能夠了解如何使用Selenium����,而且還能知道一些超級好用的小工具。
當然有人把操作網(wǎng)頁��,然后把網(wǎng)頁的關(guān)鍵內(nèi)容保存下來的應(yīng)用一律稱作網(wǎng)絡(luò)爬蟲����,好吧�����,如果你想這么爬取內(nèi)容�����,隨你���。但是�����,我更愿意稱它為網(wǎng)絡(luò)機器人����。
我今天介紹的項目使用Selenium,Selenium 是支持 web 瀏覽器自動化的一系列工具和庫的綜合項目���。Selenium 的核心是 WebDriver�����,這是一個編寫指令集的接口��,可以在許多瀏覽器中互換運行�。
閑言少敘�����,硬貨安排����。
安裝 Selenium
可以使用 pip 安裝 Python 的 Selenium 庫:pip install selenium
(可選項:要執(zhí)行項目并控制瀏覽器����,需要安裝特定于瀏覽器的 WebDriver 二進制文件��。
下載 WebDriver 二進制文件 并放入 系統(tǒng) PATH 環(huán)境變量 中.)
由于本地瀏覽器版本升級�,引起的版本不一致問題,和系統(tǒng)PATH環(huán)境變量的設(shè)置比較繁瑣�,所以我使用webdriver_manager,
安裝 Install manager:
pip install webdriver-manager
寫代碼
引入模塊:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
首先我們定義一個類Search_Baidu����, 它主要用于初始化;定義自動化步驟的方法�;結(jié)束關(guān)閉瀏覽器。
class Search_Baidu:
def __init__(self):
def search(self, keyword):
def tear_down(self):
接下來我們分別介紹每個方法的實現(xiàn)過程��。
def __init__(self): #類構(gòu)造函數(shù)��,用于初始化selenium的webdriver
url = 'https://www.baidu.com/' #這里定義訪問的網(wǎng)絡(luò)地址
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加載圖片,加快訪問速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步驟很重要�,設(shè)置為開發(fā)者模式�,防止被各大網(wǎng)站識別出來使用了Selenium
# 這里使用chrome瀏覽器,而且使用我們剛才安裝的webdriver_manager的chrome driver��,并賦值上面的瀏覽器設(shè)置options變量
self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=options)
self.wait = WebDriverWait(self.browser, 10) #超時時長為10s,由于自動化需要等待網(wǎng)頁控件的加載����,所以這里設(shè)置一個默認的等待超時,時長為10秒
def tear_down(self):
self.browser.close() #最后���,關(guān)閉瀏覽器
接下來是重頭戲���,寫我們操作瀏覽器的步驟,打開瀏覽器�,進入百度網(wǎng)頁,輸入搜索關(guān)鍵字:Selenium�,等待搜索結(jié)果,把搜索結(jié)果的題目和網(wǎng)址保存到文件里�����。
def search(self, keyword):
# 打開百度網(wǎng)頁
self.browser.get(self.url)
# 等待搜索框出現(xiàn)���,最多等待10秒����,否則報超時錯誤
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kw"]')))
# 在搜索框輸入搜索的關(guān)鍵字
search_input.send_keys(keyword)
# 回車
search_input.send_keys(Keys.ENTER)
# 等待10秒鐘
self.browser.implicitly_wait(10)
# 找到所有的搜索結(jié)果
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
# 遍歷所有的搜索結(jié)果
with open("search_result.txt","w") as file:
for result in results:
if result.get_attribute("href"):
print(result.get_attribute("text").strip())
# 搜索結(jié)果的標題
title = result.get_attribute("text").strip()
# 搜索結(jié)果的網(wǎng)址
link = result.get_attribute("href")
# 寫入文件
file.write(f"Title: {title}, link is: {link} \n")
點位網(wǎng)頁元素
這里頭有個關(guān)鍵點�,就是如何點位網(wǎng)頁元素:
比如:
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kw"]')))
還有:
self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
打個比方�����,快遞員通過地址找到你家���,給你送快遞,這里的XPATH和CSS Selector就是網(wǎng)頁元素的地址����,那么如何得到呢?
第一個就是Chrome自帶的開發(fā)者工具���,可以快捷鍵F12��,也可以自己在下圖中找到:
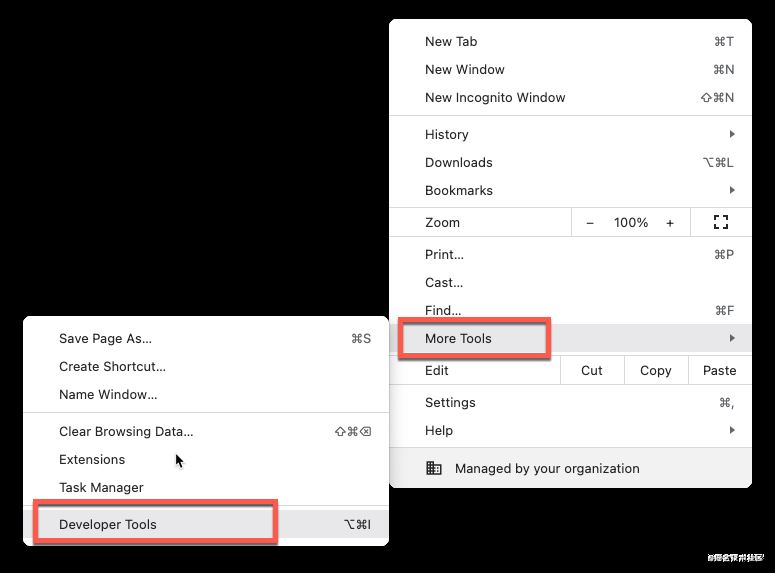
然后在百度搜索框���,右鍵:
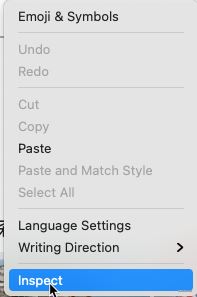
找到輸入框的HTML元素,
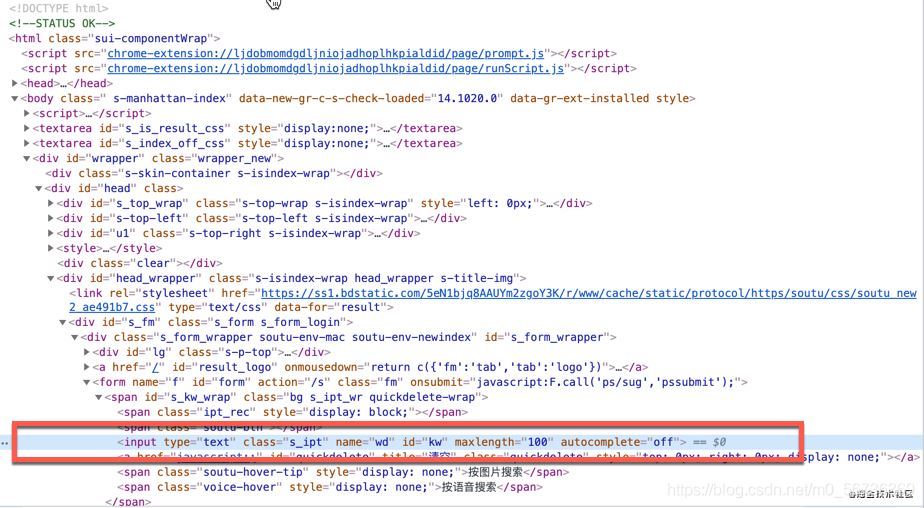
在HTML元素右鍵���,拷貝XPath地址�。
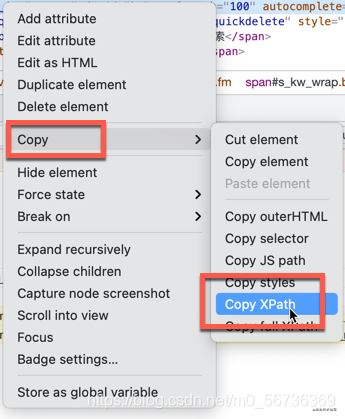
這是比較簡單的定位網(wǎng)頁元素的方法��。接下來我們定位搜索結(jié)果元素的時候����,就遇到了麻煩,如下圖:
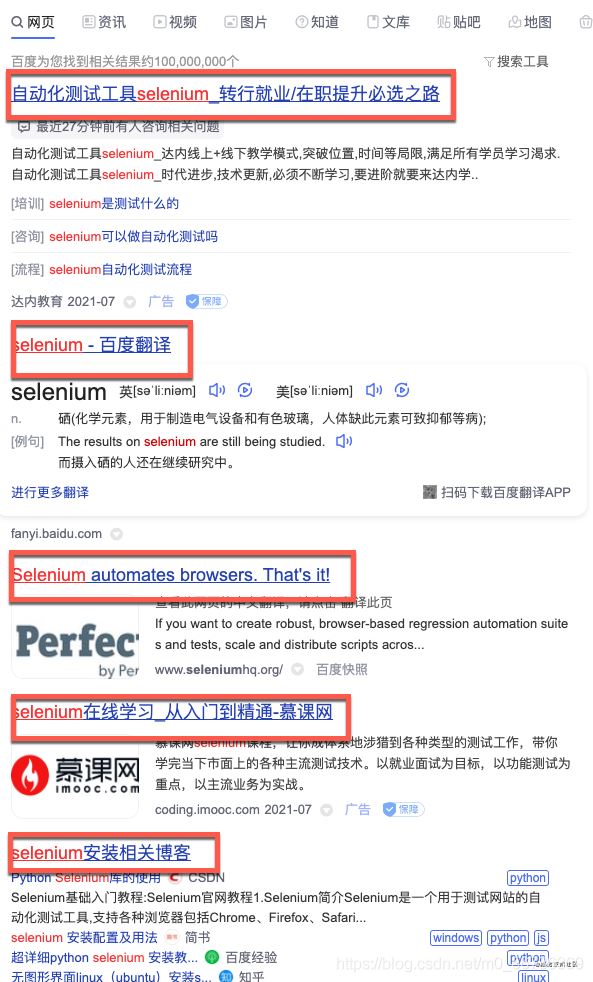
我們不能單獨的定位每個元素����,而是要找到規(guī)律,一次把所有的搜索結(jié)果找到��,然后返回一個list�����,我們好遍歷這個list��,這個怎么實現(xiàn)呢���?
接下來�����,我們請出一大神器:SelectorGadget
SelectorGadget是一個CSS Selector生成器�����,大家可以在他的官方文檔找到具體的使用說明����,我這里簡單介紹一下:
首先啟動SelectorGadget,點擊一下圖標

瀏覽器會出現(xiàn)下面的框框:

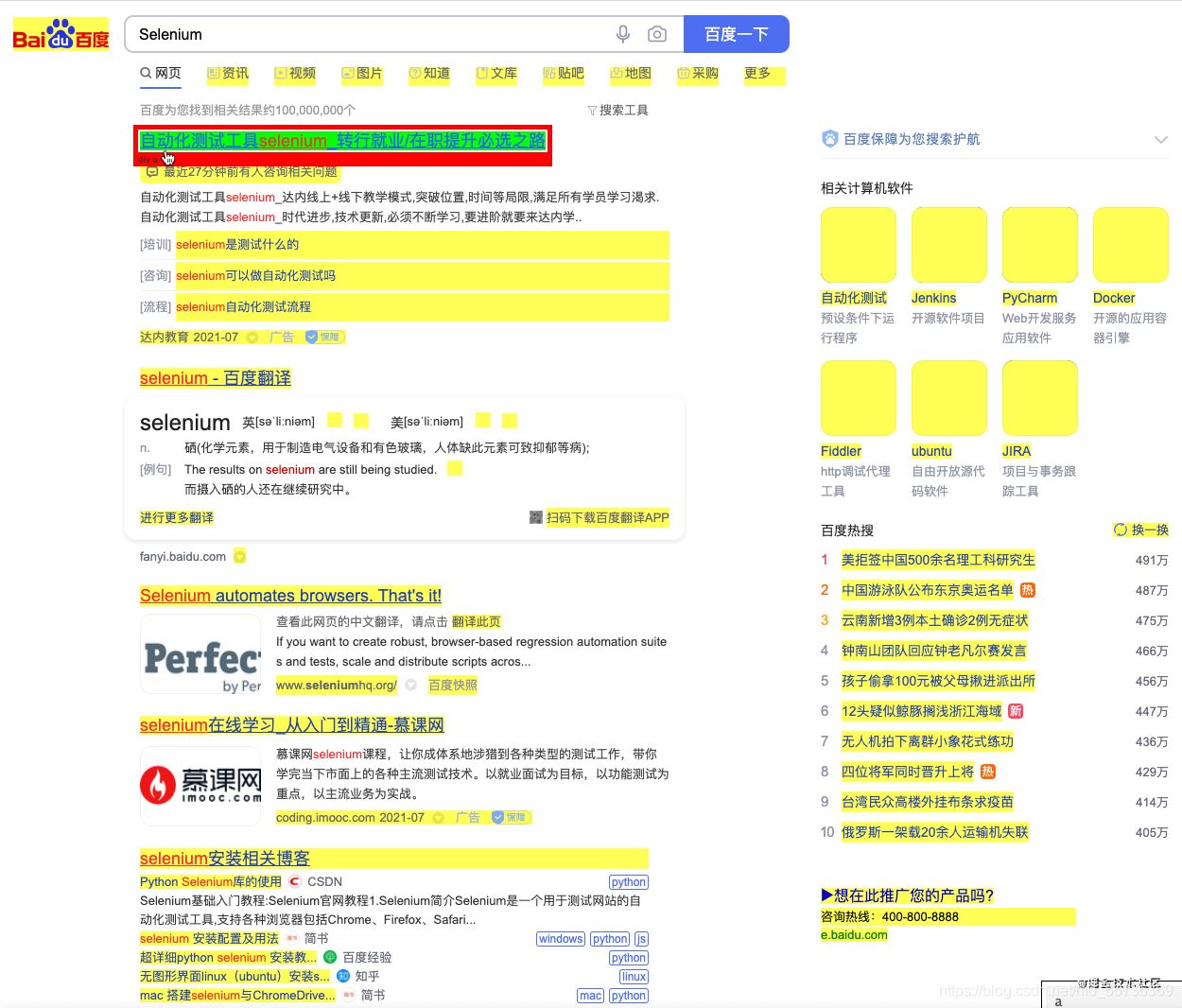
然后我們在網(wǎng)頁用鼠標左鍵�����,點擊我們要定位的元素

然后頁面會變成下面的樣子:
所有黃色的部分說明都被選擇了����,如果我們不想要的元素,右鍵點擊��,使它變?yōu)榧t色��,說明它被去掉了��。如果沒有被選擇我們又需要的元素��,我們左鍵選擇它���,使它變?yōu)榫G色�����。最后我們希望選擇的頁面元素都變成了綠色或者黃色�,如下圖:
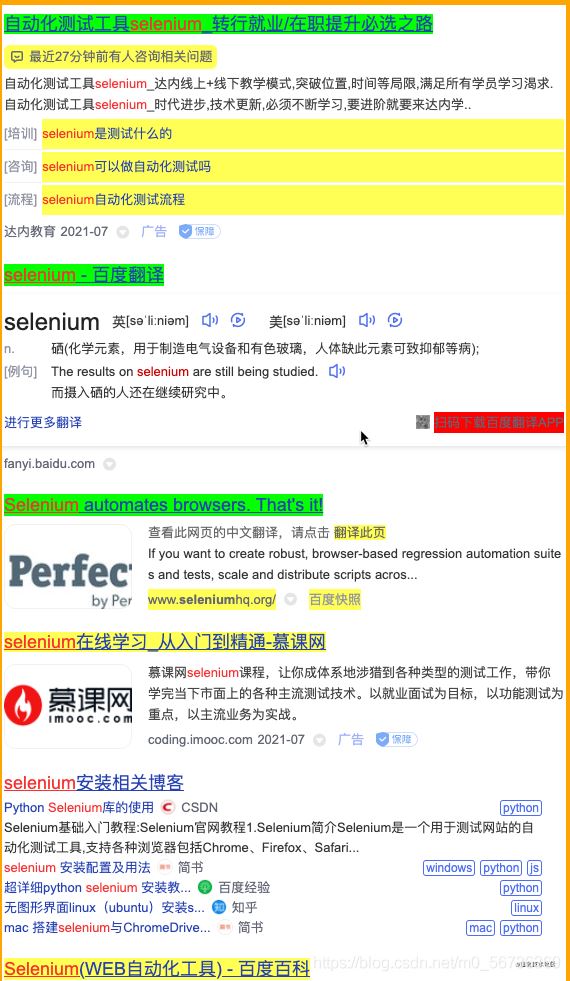
我們就可以拷貝框框里的內(nèi)容作為CSS Selector了。
通過CSS Selector找到所有的搜索結(jié)果���。
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
到此,我們就實現(xiàn)了這么個簡單的小應(yīng)用了����,其實selenium就是幫助我們自動操作網(wǎng)頁元素,所以我們定位網(wǎng)頁元素就是重中之重�,希望本文給你帶來一點幫助。
下面我附上代碼:
from datetime import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
class Search_Baidu:
def __init__(self):
url = 'https://www.baidu.com/'
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加載圖片,加快訪問速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步驟很重要����,設(shè)置為開發(fā)者模式,防止被各大網(wǎng)站識別出來使用了Selenium
self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=options)
self.wait = WebDriverWait(self.browser, 10) #超時時長為10s
def search(self, keyword):
# 打開百度網(wǎng)頁
self.browser.get(self.url)
# 等待搜索框出現(xiàn)�,最多等待10秒,否則報超時錯誤
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="kw"]')))
# 在搜索框輸入搜索的關(guān)鍵字
search_input.send_keys(keyword)
# 回車
search_input.send_keys(Keys.ENTER)
# 等待10秒鐘
self.browser.implicitly_wait(10)
# 找到所有的搜索結(jié)果
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
# 遍歷所有的搜索結(jié)果
with open("search_result.txt","w") as file:
for result in results:
if result.get_attribute("href"):
print(result.get_attribute("text").strip())
# 搜索結(jié)果的標題
title = result.get_attribute("text").strip()
# 搜索結(jié)果的網(wǎng)址
link = result.get_attribute("href")
# 寫入文件
file.write(f"Title: {title}, link is: {link} \n")
def tear_down(self):
self.browser.close()
if __name__ == "__main__":
search = Search_Baidu()
search.search("selenium")
search.tear_down()
到此這篇關(guān)于Python使用Selenium自動進行百度搜索的實現(xiàn)的文章就介紹到這了,更多相關(guān)Python Selenium自動百度搜索內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- 詳解Python 使用 selenium 進行自動化測試或者協(xié)助日常工作
- Python利用Selenium實現(xiàn)網(wǎng)站自動簽到功能
- Selenium+Python自動化腳本環(huán)境搭建的全過程
- 利用Python+Selenium破解春秋航空網(wǎng)滑塊驗證碼的實戰(zhàn)過程
- python Selenium等待元素出現(xiàn)的具體方法
- Python中Selenium對Cookie的操作方法
- python+opencv+selenium自動化登錄郵箱并解決滑動驗證的問題
- 用Python selenium實現(xiàn)淘寶搶單機器人
- 教你用Python+selenium搭建自動化測試環(huán)境
- Python selenium的這三種等待方式一定要會!
- Python爬蟲實戰(zhàn)之用selenium爬取某旅游網(wǎng)站
- 教你如何使用Python selenium
- python Web應(yīng)用程序測試selenium庫使用用法詳解
